How to Perform Exploratory Data Analysis (EDA) for Better Insights
Exploratory Data Analysis (EDA) — the foundation of every successful data project.
Before building models or dashboards, you must first understand your data deeply. In this guide, you'll learn a clear, structured approach to performing EDA for better insights and smarter decisions.
What is Exploratory Data Analysis (EDA)?
Exploratory Data Analysis is the process of analyzing datasets to summarize their main characteristics using statistics and visualizations.
The concept was popularized by John Tukey, who emphasized that we should explore first, model later.
EDA helps you:
Detect missing values
Identify outliers
Understand distributions
Discover relationships
Validate assumptions
Step-by-Step Guide to Perform EDA
1️⃣Understand Your Dataset Structure
Start by loading your dataset using Pandas.
import pandas as pd
df = pd.read_csv("data.csv")
df.head()
Check:
df.shape→ Rows & columnsdf.info()→ Data typesdf.describe()→ Statistical summary
Ask yourself:
What are numerical vs categorical features?
Is the dataset large or small?
Are there obvious inconsistencies?
2️⃣ Handle Missing Values
df.isnull().sum()
Missing values can distort insights. You can:
Drop rows/columns
Fill with mean/median
Use forward/backward fill
👉 Always analyze why data is missing before fixing it.
3️⃣ Perform Univariate Analysis (Single Variable)
Univariate analysis helps you understand each feature independently.
For Numerical Data
Use Seaborn or Matplotlib.
import seaborn as sns
sns.histplot(df["age"], kde=True)


Look for:
Skewness
Spread
Outliers
Distribution shape
4️⃣ Bivariate Analysis (Relationship Between Variables)
Understanding relationships is crucial for feature selection.
sns.scatterplot(x="age", y="salary", data=df)

Analyze:
Positive correlation
Negative correlation
No correlation
5️⃣ Correlation Matrix
Correlation helps detect multicollinearity.
import numpy as np
sns.heatmap(df.corr(), annot=True)
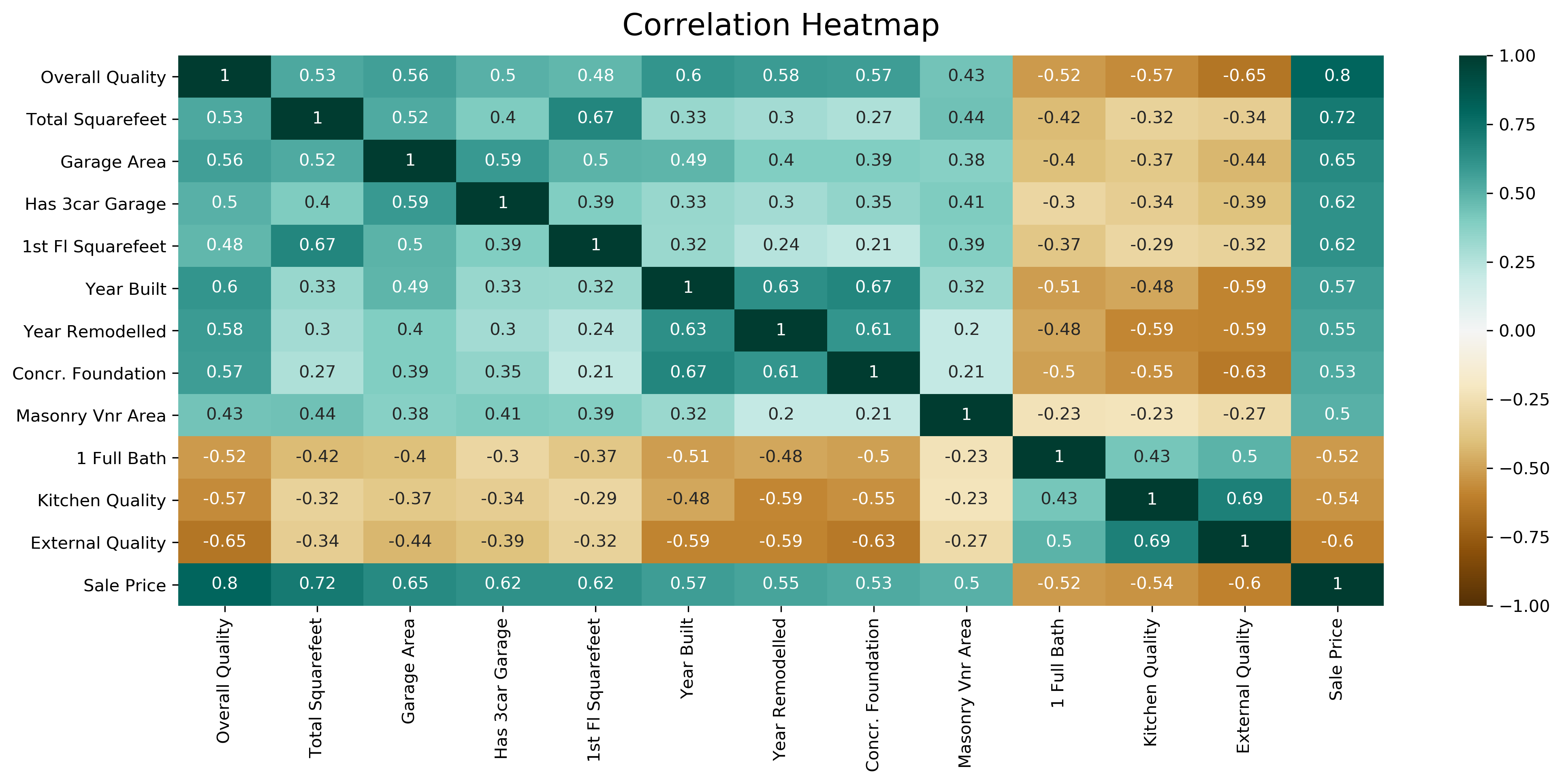
Why this matters:
Remove redundant features
Improve ML model performance
Select important variables
6️⃣ Detect Outliers
Outliers can distort mean and model predictions.
Use:
Boxplots
IQR method
Z-score method
Example (IQR Method):
Q1 = df["salary"].quantile(0.25)
Q3 = df["salary"].quantile(0.75)
IQR = Q3 - Q1
Outliers exist if value < Q1 − 1.5×IQR or > Q3 + 1.5×IQR.
📊 Best Python Libraries for EDA
Library | Purpose |
|---|---|
Pandas | Data manipulation |
NumPy | Numerical operations |
Matplotlib | Basic plotting |
Seaborn | Statistical visualization |
Plotly | Interactive dashboards |
🚀 Real-World Example
Suppose you’re building a Customer Churn Prediction model.
EDA might reveal:
Customers with higher monthly charges churn more
Long-term customers churn less
Certain contract types reduce churn
These insights improve:
Business strategy
Feature engineering
Model accuracy
Common EDA Mistakes
Jumping directly to machine learning
Ignoring missing values
Over-visualizing without extracting insights
Not documenting observations
Final EDA Checklist
Data structure understood
Missing values handled
Distributions analyzed
Relationships explored
Correlation checked
Outliers identified
Insights documented
Exploratory Data Analysis is not just a step — it’s the foundation of intelligent data-driven decisions.
Before building any ML model or dashboard:
Explore deeply. Understand patterns. Then build confidently.
Master EDA, and you master data.


